本文共 16403 字,大约阅读时间需要 54 分钟。
Elasticsearch:负责日志检索和存储(数据库,数据的检索和储存)
Logstash:负责日志的收集和分析,处理(数据的收集和处理)
Kibana:负责日志的可视化(展示web页面)
ELK组件在海量日志系统的运维中,可用于解决
- 分布式日志数据集中式查询和管理
- 系统监控,包含系统硬件和应用各个组件的监控
- 故障排查
- 安全信息和事件管理
- 报表功能
web日志处理分析
访问量突增: 网站受到攻击,竞争对手爬取我的数据
zabbix :出口带宽流量
故障现象:
客户反馈网站卡慢,
web负载不高,流量跑满了
为什么带宽涨了一倍,更新了一些页面,前端uI偷懒了,上传的图片没有处理和压缩,
总流量排名,怀疑有人攻击或爬取数据,发现网页访问频率没有增加,查看哪个网站带宽高针对哪个网站分析
用户 -----> kibana ------> ElasticSeach ----> logstash <-----web
ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful API的Web接口
Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便
– 实时分析
– 分布式实时文件存储,并将每一个字段都编入索引 – 文档导向,所有的对象全部是文档 – 高可用性,易扩展,支持集群(Cluster)、分片和复 制(Shards 和 Replicas) – 接口友好,支持JSON
– Elasticsearch没有典型意义的事务
– Elasticsearch是一种面向文档的数据库 – Elasticsearch没有提供授权和认证特性
es部分:
Node:装有一个ES服务器的节点
Cluster:有多个Node组成的集群
Document:一个可被搜索的基础信息单元
Index:拥有相似特征的文档的集合
Type:一个索引中科院定义一种或者多种类型
Filed:是ES最小单位,相当于数据的某一列
Shards:索引的分片,每一个分片就是一个Shard
Replicas:索引的拷贝
| ES | 关系型数据库 |
| Indices索引 | Databases数据库 |
| Types类型 | Tables表 |
| Documents文档 | Rows行 |
| Fields域(字段) | Columns列 |
| Mapping | Schema |
| Everything is indexed | index |
| Query DSL | SQL |
| GET http://... | SELECT * FROM table... |
| PUT http:// | UPDATE table SET |
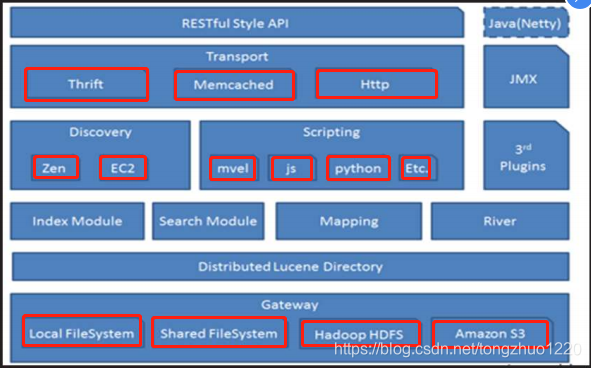
架构图
环境192.168.5.51-55
本次安装使用ansible批量部署
真机]# mkdir elk
cd elk
[root@tedu-cn elk]# cat ansible.cfg
[defaults] inventory = myhost host_key_checking = False[root@tedu-cn elk]# cat essetup.yml[root@tedu-cn elk]# cat hosts # ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4192.168.1.51 es1 192.168.1.52 es2 192.168.1.53 es3 192.168.1.54 es4 192.168.1.55 es5
--- - hosts: es remote_user: root tasks: - copy: src: local.repo dest: /etc/yum.repos.d/local.repo owner: root group: root mode: 0644 - name: install elasticsearch yum: name: java-1.8.0-openjdk,elasticsearch state: installed - template: src: elasticsearch.yml dest: /etc/elasticsearch/elasticsearch.yml owner: root group: root mode: 0644 notify: reload elasticsearch tags: esconf - service: name: elasticsearch enabled: yes handlers: - name: reload elasticsearch service: name: elasticsearch state: restarted [root@tedu-cn elk]# cat local.repo #光盘为环境自带,请自行下载
[local_repo] name=CentOS-$releasever - Base baseurl="ftp://192.168.5.254/centos-1804" enabled=1 gpgcheck=0[local_elk]
name=CentOS-$releasever - ELK baseurl="ftp://192.168.5.254/public" enabled=1 gpgcheck=0[root@tedu-cn elk]# cat elasticsearch.yml
......
cluster.name: nsd1902
node.name: { {ansible_hostname}} network.host: 0.0.0.0 discovery.zen.ping.unicast.hosts: ["es1", "es2", "es3"] ........
ES插件:
kopf插件:管理工具,提供了对ES集群操作的API
bigdesk插件:集群监控工具,可以通过他来查看es集群的各种状态,如cpu,内存,索引数据,搜索情况,http连接数等
以55做插件
cd /usr/share/elasticsearch/bin
[root@es5 bin]# ./plugin list
[root@es5 bin]# lftp 192.168.5.254[root@es5 bin]# ./plugin install ftp://192.168.5.254/pub/elasticsearch-head-master.zip
[root@es5 bin]# ./plugin install ftp://192.168.5.254/pub/elasticsearch-kopf-master.zip [root@es5 bin]# ./plugin install ftp://192.168.5.254/pub/bigdesk-master.zip [root@es5 bin]# ./plugin list Installed plugins in /usr/share/elasticsearch/plugins: - head - kopf - bigdesk
真机访问
kopf/
HTTP
http请求由3部分组成(请求头,消息报头,请求正文)
请求行以一个方法符号开头,以空格分开,后面跟着请求的URL和协议版本
格式: Method Request-URI HTTP-Version CRLF
curl常见参数:
-A 修改请求agent
-X 设置请求方法
-i 显示返回头信息
http请求方法:
GET查 POST改 HEAD OPTIONS PUT增 DELETE删 TRACE CONNECT
RESTful API调用
Elasticsearch提供了一系列RESTful的API
-检查集群、节点、索引的健康度、状态和统计
-管理集群、节点、索引的数据及元数据
-对索引进行CRUD操作及查询操作
-执行其他高级操作如分页、排序、过滤等
_cat API 查询集群状态,节点信息
v 参数显示详细信息
help 显示帮助信息
nodes 查询节点状态信息
indices 索引信息
curl http://192.168.5.51:9200/_cat/nodes?v
curl http://192.168.5.51:9200/_cat/indices?v
curl http://192.168.5.51:9200/_cat/health?help
POST或PUT数据使用json格式
[root@es5 bin]# curl -XPUT http://192.168.5.51:9200/t3 -d'
> { > "settings":{ > "index":{ > "number_of_shards": 5, > "number_of_replicas": 1 > } > } > }{"acknowledged":true}[root@es5 bin]#
[root@es5 bin]# curl -XPUT http://192.168.5.51:9200/t3/n1/5 -d '
{ "姓名": "啊鹏", "年龄": "25", "爱好": "游戏"}'
批量导入数据使用POST方式,数据格式为json,url
编码使用data-binary – 导入含有index配置的json文件 # gzip –d logs.jsonl.gz gzip -d shakespeare.json.gzgzip -d accounts.json.gz
curl -XPOST http://192.168.5.52:9200/_bulk --data-binary @logs.jsonl
curl -XPOST http://192.168.5.53:9200/_bulk --data-binary @shakespeare.json
curl -XPOST http://192.168.5.51:9200/accounts/ac/_bulk --data-binary @accounts.json
json文件里没有库需加上 ,会自动创建
map 映射
• mapping: – 映射:创建索引的时候,可以预先定义字段的类型及 相关属性 – 作用:这样会让索引建立得更加的细致和完善 – 分类:静态映射和动态映射 – 动态映射:自动根据数据进行相应的映射 – 静态映射:自定义字段映射数据类型
kibana
– 数据可视化平台工具
• 特点:
– 灵活的分析和可视化平台 – 实时总结流量和数据的图表 – 为不同的用户显示直观的界面 – 即时分享和嵌入的仪表板
新建一台192.168.5.50 , 配/etc/hosts, 配yum, 配静态ip (和上面的配置一致)
安装kibana,yum源里有包,小编这里是直接yum安装
[root@kibana ~]# vim /opt/kibana/config/kibana.yml
server.port: 5601 端口号
server.host: "0.0.0.0" 本机监听地址 elasticsearch.url: "http://es2:9200" elasticsearch地址 kibana.index: ".kibana" 索引名称 kibana.defaultAppId: "discover" 默认页面 elasticsearch.pingTimeout: 1500 elasticsearch.requestTimeout: 30000 elasticsearch.startupTimeout: 5000[root@kibana ~]# systemctl start kibana
[root@kibana ~]# systemctl enable kibana
[root@kibana ~]# ss -nutlp | grep 5601真机浏览器访问http://192.168.5.50:5601/
查看全部是否为绿色(green)
然后访问 查看kibana部分是否导入

logstash
• 是一个数据采集、加工处理以及传输的工具
• 特点 – 所有类型的数据集中处理 – 不同模式和格式数据的正常化 – 自定义日志格式的迅速扩展 – 为自定义数据源轻松添加插件
kibana--->elastsearch
/|\
| 写入
|
logstash(数据源-->input -----> filter----> output )
• Logstash里面的类型
– 布尔值类型: ssl_enable => true – 字节类型: bytes => "1MiB" – 字符串类型: name => "xkops" – 数值类型: port => 22 – 数组: match => ["datetime","UNIX"] – 哈希: options => {k => "v",k2 => "v2"} – 编码解码: codec => "json" – 路径: file_path => "/tmp/filename" – 注释: #
• Logstash条件判断
– 等于: == – 不等于: != – 小于: < – 大于: > – 小于等于: <= – 大于等于: >= – 匹配正则: =~ – 不匹配正则: !~
• Logstash条件判断
– 包含: in – 不包含: not in – 与: and – 或: or – 非与: nand – 非或: xor – 复合表达式: () – 取反符合: !()
– Logstash依赖Java环境,需要安装java-1.8.0-openjdk
– Logstash没有默认的配置文件,需要手动配置 – Logstash安装在/opt/logstash目录下环境准备:
192.168.5.51 es1
192.168.5.52 es2 192.168.5.53 es3 192.168.5.54 es4 192.168.5.55 es5 192.168.5.50 kibana192.168.5.58 logstash #新创建,要求4G内存 192.168.5.56 web #新创建[root@logstash ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.5.51 es1 192.168.5.52 es2 192.168.5.53 es3 192.168.5.54 es4 192.168.5.55 es5 192.168.5.50 kibana 192.168.5.58 logstash 192.168.5.56 web
[root@logstash ~]# cat /etc/yum.repos.d/local.repo 配置yum源
[local_repo] name=CentOS-$releasever - Base baseurl="ftp://192.168.5.254/centos-1804" enabled=1 gpgcheck=1 [elk] name=elk baseurl=ftp://192.168.5.254/elk enabled=1 gpgcheck=0[root@logstash ~]# yum -y install java-1.8.0-openjdk logstash
input{} 配置读取数据
filter{} 配置过滤,处理日志
output{} 配置输出部分
[root@logstash ~]# cd /etc/logstash/
/opt/logstashlogstash -f logstash.conf
[root@logstash logstash]# touch logstash.conf
[root@logstash logstash]# vim logstash.conf| input { stdin{} #标准输入 }filter{} output{ stdout{} #标准输出,这里指不做任何操作扔出来 } |
[root@logstash logstash]# /opt/logstash/bin/logstash -f logstash.conf #-f指定配置文件/etc/logstash/logstash.conf
Settings: Default pipeline workers: 2
Pipeline main startedasoldfagpu #瞎写一些字符串敲回车 2019-06-23T11:20:54.700Z logstash asoldfagpu #时间戳 + 主机名 + 上面输入的内容
配置别名
[root@logstash logstash]# vim /etc/bashrc
alias logstash='/opt/logstash/bin/logstash'
[root@logstash ~]# cd /opt/logstash/bin/
[root@logstash bin]# lslogstash logstash.lib.sh logstash-plugin.bat plugin.bat rspec.bat logstash.bat logstash-plugin plugin rspec setup.batlogstash-plugin #安装删除插件用的
[root@logstash bin]# ./logstash-plugin list
第一列:logstash插件, 第二列:代表这个插件只能运行在哪个区域, 第三列:插件名字
查看官方文档
codec类插件
[root@logstash logstash]# vim /etc/logstash/logstash.conf
input {
stdin{ codec => "json" } }filter{}
output{
stdout{ codec => "rubydebug" } }[root@logstash bin]# logstash -f /etc/logstash/logstash.conf
Settings: Default pipeline workers: 2 Pipeline main started{"a":1, "b":2, "c":3} #输入json格式 { "a" => 1, "b" => 2, "c" => 3, "@version" => "1", "@timestamp" => "2019-06-23T11:39:15.694Z", "host" => "logstash"}
» » File input plugin
Ctrl + f 查找input
[root@logstash logstash]# vim /etc/logstash/logstash.conf
input {
file { path => ["/tmp/a.log", "/var/tmp/b.log"] } } filter{}output{
stdout{ codec => "rubydebug" } } [root@logstash logstash]# touch /tmp/a.log [root@logstash logstash]# touch /var/tmp/b.log
开2个终端logstash测试
[root@logstash logstash]# echo A_${RANDOM} >>/tmp/a.log #终端1写入数据
[root@logstash ~]# logstash -f /etc/logstash/logstash.conf #终端2输出数据
Settings: Default pipeline workers: 2 Pipeline main started { "message" => "A_12382", "@version" => "1", "@timestamp" => "2019-06-23T11:52:58.212Z", "path" => "/tmp/a.log", "host" => "logstash" }[root@logstash logstash]# echo B_${RANDOM} >>/var/tmp/b.log #终端1写入数据
[root@logstash bin]# logstash -f /etc/logstash/logstash.conf #终端2输出数据,可以监控多个文件
Settings: Default pipeline workers: 2 Pipeline main started { "message" => "B_27270", "@version" => "1", "@timestamp" => "2019-06-23T11:58:18.043Z", "path" => "/var/tmp/b.log", "host" => "logstash" }Ctrl + c停止后,终端1继续写数据,终端2再启动时,从上次读取的位置开始读取,只读取新增加(停止后增加的也被读取)的数据,之前读取过的不读,
sincedb_path 文件,默认放在用户的家目录里面 ~/.sincedb_e9a1772295a869da80134b5c4e75816e
[root@logstash logstash]# echo A_${RANDOM} >>/tmp/a.log
[root@logstash logstash]# echo B_${RANDOM} >>/var/tmp/b.log
[root@logstash ~]# rm -rf .sincedb_e9a1772295a869da80134b5c4e75816e 把指针文件删了
[root@logstash ~]# vim /etc/logstash/logstash.conf
input {
file { path => ["/tmp/a.log", "/var/tmp/b.log"] sincedb_path => "/var/lib/logstash/since.db" #记录读取文件的位置 start_position => "beginning" #配置第一次读取文件从什么地方开始#指针文件不存在的时候 1.从文件头开始读,读取完整的数据(beginning) 2.舍弃之前所有旧数据,从当前位置开始读(end默认)
} } filter{}output{
stdout{ codec => "rubydebug" } }
[root@logstash bin]# logstash -f /etc/logstash/logstash.conf
之前的旧数据也输出来了
[root@logstash ~]# vim /etc/logstash/logstash.conf
input {
file { path => ["/tmp/a.log", "/var/tmp/b.log"] sincedb_path => "/var/lib/logstash/since.db" start_position => "beginning" type => "testlog" #打标签,,随便打,在后面的程序里调用和判断 } } filter{}output{
stdout{ codec => "rubydebug" } }
[root@logstash bin]# logstash -f /etc/logstash/logstash.conf
[root@logstash ~]# echo A_${RANDOM} >>/tmp/a.log
web虚拟机 192.168.5.56上启一个http服务,然后用真机浏览器访问,并读取/var/log/httpd/access_log的其中有浏览器标示的行复制到logstash的/tmp/a.log
vim /tmp/a.log
192.168.5.254 - - [23/Jun/2019:20:55:15 +0800] "GET /noindex/css/fonts/Bold/OpenSans-Bold.ttf HTTP/1.1" 404 238 "http://192.168.5.56/noindex/css/open-sans.css" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36"
[root@logstash bin]# logstash -f /etc/logstash/logstash.conf 查看
[root@logstash ~]# vim /etc/logstash/logstash.conf
input { file { path => [ "/tmp/a.log", "/var/tmp/b.log" ] # sincedb_path => "/var/lib/logstash/since.db" sincedb_path => "/dev/null" #方便实验,每次的指针文件都丢弃,每次启动时就可以看全部内容数据了 start_position => "beginning" type => "tsetlog" } } filter{} output { stdout { codec => "rubydebug" } }
查找filter,格式如下

里面记录了httpd日志格式含义
金步国有个翻译官方文档
正则文件: /opt/logstash/vendor/bundle/jruby/1.9/gems/logstash-patterns-core-2.0.5/patterns/grok-patterns/
正则宏: /opt/logstash/vendor/bundle/jruby/1.9/gems/logstash-patterns-core-2.0.5/patterns/grok-patterns
IPV4 (?<![0-9])(?:(?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5])[.](?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5])[.](?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5])[.](?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5]))(?![0-9])
COMBINEDAPACHELOG # http的宏
- filter grok插件
– 解析各种非结构化的日志数据插件
– grok使用正则表达式把飞结构化的数据结构化 – 在分组匹配,正则表达式需要根据具体数据结构编写 – 虽然编写困难,但适用性极广 – 几乎可以应用于各类数据格式: grok{
match => ["message", "%{IP:ip}, (?<key>reg) " ] }• grok正则分组匹配
- – 匹配ip时间戳和请求方法
"(?<ip>(\d+\.){3}\d+) \S+ \S+
(?<time>.*\])\s+\"(?<method>[A-Z]+)"]- – 使用正则宏
%{IPORHOST:clientip} %{HTTPDUSER:ident} %{USER:auth}
\[%{HTTPDATE:timestamp}\] \"%{WORD:verb}- – 最终版本
%{COMMONAPACHELOG} \"(?<referer>[^\"]+)\"
\"(?<UA>[^\"]+)\"[root@logstash ~]# vim /etc/logstash/logstash.conf
input {
file { path => [ "/tmp/a.log", "/var/tmp/b.log" ] # sincedb_path => "/var/lib/logstash/since.db" sincedb_path => "/dev/null" start_position => "beginning" type => "tsetlog" } } filter { grok { match => { "message" => "%{COMBINEDAPACHELOG}"} } }output {
stdout { codec => "rubydebug" } }
| [root@logstash bin]# logstash -f /etc/logstash/logstash.conf "message" => "192.168.5.254 - - [23/Jun/2019:20:55:15 +0800] \"GET /noindex/css/fonts/Bold/OpenSans-Bold.ttf HTTP/1.1\" 404 238 \"http://192.168.5.56/noindex/css/open-sans.css\" \"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36\"", "@version" => "1", "@timestamp" => "2019-06-23T14:02:58.307Z", "path" => "/tmp/a.log", "host" => "logstash", "type" => "tsetlog", "clientip" => "192.168.5.254", "ident" => "-", "auth" => "-", "timestamp" => "23/Jun/2019:20:55:15 +0800", "verb" => "GET", "request" => "/noindex/css/fonts/Bold/OpenSans-Bold.ttf", "httpversion" => "1.1", "response" => "404", "bytes" => "238", "referrer" => "\"http://192.168.5.56/noindex/css/open-sans.css\"", "agent" => "\"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36\"" } |
清空数据
[root@logstash ~]# curl -XDELETE http://es1:9200/*
{"acknowledged":true}[root@logstash ~]#[root@kibana ~]# systemctl restart kibana #重启就恢复了(恢复初始化状态)
[root@logstash ~]# vim /etc/logstash/logstash.conf
input {
file { path => [ "/tmp/a.log", "/var/tmp/b.log" ] sincedb_path => "/var/lib/logstash/since.db" # sincedb_path => "/dev/null" 这里去掉,不然每次都会写一次全部进数据库 start_position => "beginning" type => "tsetlog" } } filter { grok { match => { "message" => "%{COMBINEDAPACHELOG}"} } }output {
stdout { codec => "rubydebug" } elasticsearch { hosts => ["es1:9200", "es2:9200", "es3:9200"] #配置主机地址,放在数组里,多台防止单台坏了没得用 index => "weblog" #索引名字,随便取 flush_size => 2000 #在运行elastsearch攒够2000字节写一次(默认来一个写一次频繁写,影响性能) idle_flush_time => 10 #10秒内更新一次,不管有没有新数据都写一次,实时性的更新 } }
空的
[root@logstash bin]# logstash -f /etc/logstash/logstash.conf
点击[数据浏览]这时有数据了,数据被同步到数据库了
web到elk的数据流打通
[root@logstash ~]# vim /etc/logstash/logstash.conf
input {
file { path => [ "/tmp/a.log", "/var/tmp/b.log" ] sincedb_path => "/dev/null" start_position => "beginning" type => "tsetlog" } beats { #接收beats类软件发送过来的数据 port => 5044 }}
filter { grok { match => { "message" => "%{COMBINEDAPACHELOG}"} } }output {
stdout { codec => "rubydebug" } elasticsearch { hosts => ["es1:9200", "es2:9200", "es3:9200"] index => "weblog" flush_size => 2000 idle_flush_time => 10 } }
[root@logstash bin]# logstash -f /etc/logstash/logstash.conf
[root@logstash ~]# ss -nutlp tcp LISTEN 0 50 :::5044 :::* users:(("java",pid=2842,fd=7))
[root@logstash ~]# curl -XDELETE http://es3:9200/weblog 清空日志
{"acknowledged":true}[root@logstash ~]#
[root@web ~]# vim /etc/yum.repos.d/local.repo
[local_repo]
name=CentOS-$releasever - Base baseurl="ftp://192.168.5.254/centos-1804" enabled=1 gpgcheck=0[elk]
name=elk baseurl=ftp://192.168.5.254/elk enabled=1 gpgcheck=0
- filebeat
安装 filebeat.x86_64.0.1.2.3-1
#由于logstash依赖JAVA环境,而且占用资源非常大,因此会使用更轻量的filebeat替代
[root@web ~]# cd /etc/filebeat/
[root@web filebeat]# ls filebeat.template.json filebeat.yml [root@web filebeat]# grep -Pv "^\s*(#|$)" filebeat.yml #修改前 filebeat: prospectors: - paths: - /var/log/*.log input_type: log registry_file: /var/lib/filebeat/registry #需改到http的日志路径下 output: elasticsearch: hosts: ["localhost:9200"] #需注释掉 shipper: logging: files: rotateeverybytes: 10485760 # = 10MB[root@web filebeat]# vim /etc/filebeat/filebeat.yml #修改后
14 paths: 15 - /var/log/httpd/access_log72 document_type: apache_log
183 # elasticsearch:
188 # hosts: ["localhost:9200"]
278 logstash:
280 hosts: ["192.168.5.58:5044"]
[root@web filebeat]# systemctl restart filebeat
[root@logstash ~]# vim /etc/logstash/logstash.conf
input {
file { path => [ "/tmp/a.log" ] sincedb_path => "/var/lib/logstash/since.db" start_position => "beginning" type => "tsetlog" } beats { port => 5044 } } filter { if [type] == "apache_log" { grok { match => { "message" => "%{COMBINEDAPACHELOG}"} } } }output {
# stdout { # codec => "rubydebug" # } #关闭屏幕输出 if [type] == "apache_log" { elasticsearch { hosts => ["es1:9200", "es2:9200", "es3:9200"] index => "weblog" flush_size => 2000 idle_flush_time => 10 } } }
[root@logstash bin]# logstash -f /etc/logstash/logstash.conf
用其他主机 ab -n 1000 -c 1000 http://192.168.5.56/ (前提需装httpd-tools)
查看数据
查看图型数据,并制作饼图查看哪个访问最高
转载地址:http://hriqi.baihongyu.com/